
Introduction
In Part 1 (SQL Server Always On Across Two Data Centers with Dual Witnesses and DNS CNAME),
I walked through how we designed and implemented a more resilient SQL Server
Always On Availability Group architecture across two data centers, using dual
file share witnesses and a DNS CNAME to simplify failover and
enhance high availability.
Now,
in Part 2, we put that setup to the test.
This
blog focuses on failover testing—a crucial step in validating any high
availability or disaster recovery solution. I’ll simulate real-world failure
scenarios, including the complete loss of the primary data center (along
with its witness and replica) and the failure of the DR data center.
You’ll see how the system handles these events in both manual and automatic
failover modes, and how our configuration ensures continuity without manual
reconfiguration or data loss.
Whether
you're preparing for disaster recovery testing or simply validating your SQL
Server HA setup, these test cases and results will help you understand what to
expect and how to respond when failure happens.
Test Scenario 1: Simulate a failure of the secondary data center when the availability group is configured for manual failover, and observe how the system behaves under this configuration.
Consideration:
- SQLNODE1,
SQLNODE2, WitnessSite1, and WitnessSite2 are online and operational.
- Primary
Replica: SQLNODE1
- Secondary
Replica: SQLNODE2
- Witness:
WitnessSite2
The following image shows that Primary
Replica is SQLNODE1 and Secondary Replica: SQLNODE2

The following image shows that the witness is WitnessSite2

1.1. Set the cluster to manual failover mode.
Right-click
on the testag (availability group) and select the properties

Change
the failover group from Automatic to Manual.

Refresh
the availability group dashboard, and you can see that the Failover Mode has
been changed to manual.

1.2. Check Preferred owner
On
SQLNODE1, go to the Failover Cluster Manager >> Roles >> Right
click on the availability group (testag) >> select Properties

Check
both of the SQLNODE1 and SQLNODE2 nodes and click apply and OK

1.3. We will do the crash simulation of datacenter2.

Shut
down the virtual machines SQLNODE2 (the secondary replica) and WitnessSite2
(the current witness).

Because
both the secondary replica and the witness are unavailable (the majority of the
cluster configuration), the availability group will fail.

Refreshing
the Failover Group dashboard in SSMS on SQLNODE1 (the primary replica) shows
the Replica Role as 'Resolving' and the availability group in a failed state.

Clicking
on a database in the 'testag' availability group, such as AdventureWorks2019,
results in the following error:

1.4. On the DNS server, change the CNAME to WitnessSite1.
Now go to the DNS Server and change the witness CNAME to point to witnesssite1. Go to Server Manager >> Tools >> DNS

Double-click the witness CName and change WintessSite2 to WitnessSite1.

The
above indicates that the witness CName has been changed to WitnessSite1.amir.net.

When
checked again, the CNAME resolves to WitnessSite1 using nslookup in SQLNODE1.

1.5. Restart first WitnessSite1 and then
SQLNODE1
With the cluster configured for Manual Failover, a restart of WitnessSite1 must be done in SQLNODE1. This allows the Failover Cluster Manager to recognize the updated CNAME.
Note: In automatic failover mode, you don’t even need to
restart—the failover will occur automatically.
1.6. Check Failover Cluster Manager and SSMS.
Now,
the Availability group and the databases are up and running on SQLNODE1
(primary replica).
NOTE:
If the availability group doesn't start after restarting WitnessSite1 and
SQLNODE1, shut down both VMs, then start WitnessSite1, followed by SQLNODE1.
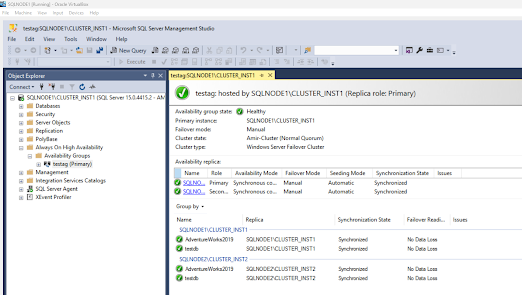
The
following image shows that Availability Group testag is up and running.

SQLNODE2
(secondary replica) is down

Logging into the SQLNODE1 instance via SSMS confirms that the AdventureWorks2019 database is accessible.
1.7. Start SQLNODE2 (secondary replica) and then WintessSite2
With
the primary node (SQLNODE1) and the witness (WitnessSite1) online, starting the
SQLNODE2 VM should allow it to rejoin the availability group.

Now,
Everything is up and running.
NOTE:
Remember to start WitnessSite2.
Test Scenario 2: Simulate a failure of the Primary data center when the availability group is configured for manual failover, and observe how the system behaves under this configuration.
In
this test, we simulate a failure of the primary datacenter while the availability
group is configured for manual failover. This scenario helps validate how
the system behaves when the active replica, its associated witness, and the
core database services become unavailable. Since the failover mode is manual,
no automatic failover is expected. The goal is to confirm whether the secondary
replica remains synchronized and ready, and to verify the necessary steps to
manually initiate failover and restore availability from the secondary
datacenter.
Consideration:
- SQLNODE1,
SQLNODE2, WitnessSite1, and WitnessSite2 are online and operational.
- Primary
Replica: SQLNODE1
- Secondary
Replica: SQLNODE2
- Witness:
WitnessSite1
- Ensure the
cluster is in Manual Failover mode. If not, change it using the steps in
section 1.1.
The following image shows that Primary Replica: SQLNODE1 and Secondary Replica: SQLNODE2 and Failover Mode is Manual

The following
image shows that Witness: WitnessSite1

2.1. Check Preferred owner
On
SQLNODE1, go to the Failover Cluster Manager >> Roles >> Right
click on the availability group (testag) >> select Properties

Check
both of the SQLNODE1 and SQLNODE2 nodes and click apply and OK

2.2. We will do the crash simulation of datacenter1.
Shut
down the virtual machines SQLNODE1 (the primary replica) and WitnessSite1 (the
current witness).

Because
both the primary replica (SQLNODE1) and the witness are unavailable (the
majority of the cluster configuration), the availability group will fail.

Refreshing
the Failover Group dashboard in SSMS on SQLNODE2 (the secondary replica) shows
the Replica Role as 'Resolving' and the availability group in a failed state.

2.3. On the DNS server, change the CNAME to WitnessSite2.
Now go to the DNS Server and change the witness CNAME to point to witnesssite2. (Go to Server Manager >> Tools >> DNS)

Double-click
the witness CName and change WintessSite2 to WitnessSite1.

The
above screenshot shows that the witness CName has been changed to WitnessSite2.amir.net.

When
checked again, the CNAME resolves to WitnessSite1 using nslookup in SQLNODE2.

2.4. Restart first WitnessSite2 and then SQLNODE2
With
the cluster configured for Manual Failover, the WitnessSite2 must be restarted
(current witness) and then SQLNODE2 (secondary replica). This allows the
Failover Cluster Manager to recognize the updated CNAME.
2.5. Check Failover Cluster Manager and SSMS.
Now,
we can see that the Availability group is down, and the databases are down on
SQLNODE2 (secondary replica).

SQLNODE1
(primary replica) is down

Logging
into the SQLNODE2 instance via SSMS, we can confirm that the AdventureWorks2019
database is not accessible, and the availability group dashboard shows
resolving status.

2.6. Start the secondary replica using PowerShell
On
SQLNODE2, run PowerShell as administrator by right-clicking the PowerShell icon
and selecting 'Run as administrator'

To
check the availability group's status, run the following command:
Get-ClusterResource -Name "testag"
To
check the availability group's owner nodes, run the following command:
Note:
In the following command, testag is the name of my availability group.
Get-ClusterResource -Name "testag" | Get-ClusterOwnerNode
If
both nodes are not listed as owner nodes for the availability group, use the
following command to add them.
Get-ClusterResource -Name "testag" | Set-ClusterOwnerNode -Owners SQLNODE1,SQLNODE2
Use
the following command to perform a manual failover. This will also bring the
availability group online.
sqlcmd -S sqlnode2 -E -Q "ALTER AVAILABILITY GROUP [testag] FORCE_FAILOVER_ALLOW_DATA_LOSS;"
The following image shows the output of executing above commands in my test environment.

Check
the availability group status and confirm that it is up and running.

The
availability group dashboard shows the databases are up and running on SQLNODE2
(new primary replica) and ready for use.

2.7. Start the SQLNODE1 virtual machine (new secondary replica).
After
starting the SQLNODE1 VM, we can see that SQLNODE1 has rejoined the
availability group.

The availability group dashboard in SSMS shows SQLNODE1 (the secondary replica) is online but not synchronizing, and the databases on both SQLNODE1 and SQLNODE2 are also not synchronizing.

Running
the following command on both nodes will synchronize the databases.
Use master go ALTER DATABASE [AdventureWorks2019] SET HADR RESUME; ALTER DATABASE [testdb] SET HADR RESUME;
After
running the above code on SQLNODE2 (the primary replica), the databases are now
synchronized.

Check the availability group dashboard on SQLNODE2 (the primary replica) and confirm that all nodes and databases are synchronized.

By completing these failover tests, we’ve validated the
resiliency of our SQL Server Always On configuration across two datacenters
using dual file share witnesses and a DNS CNAME. This setup ensures that
failover—whether manual or automatic—can be handled smoothly without the need
to dismantle or rebuild the availability group during a disaster.
If you haven’t already, make sure to check out Part 1 (SQL Server Always On Across Two Data Centers with Dual Witnesses and DNS CNAME) of this series, where I walk through the architecture and configuration steps that made this level of resilience possible. Together, these two blogs provide a complete guide to building and testing a highly available SQL Server environment designed for real-world disaster recovery.



No comments:
Post a Comment